Warning:
If you are implementing HSTS on your website and using the www subdomain, your site will not be eligible for the HSTS preload list if you use one redirect. You can either use two redirects or use the root domain as your primary site.
You can learn more HSTS and the www subdomain implementation here.
The rampant misuse of the .htaccess file is without a doubt my greatest pet peeve concerning .htaccess. The destruction caused by poorly written rewrite rules to correct duplicate content is a close second.
Let me explain the problem... and my problem with the typical solutions.
You can use the .htaccess file to force your site to only use https:// or only use www. as the subdomain. This can help ensure that your site does not have duplicate pages. Every search engine optimization (SEO) specialist knows that duplicate content is bad.
The important thing to understand is that almost every out-of-the-box CMS creates duplicate content. In fact, most can create eight different versions of any single page if your site does not have the correct rewrite rules.
The duplicate content problem
Let’s say you are the webmaster for a website and it has an SSL (Secure Socket Layer) installed. If you have not created any rewrite rules, all of the following pages probably return a valid 200 page.
http://example.com/bloghttp://example.com/blog/http://www.example.com/bloghttp://www.example.com/blog/https://example.com/bloghttps://example.com/blog/https://www.example.com/bloghttps://www.example.com/blog/
The problem here is that you can have http:// or https://, on top of www. or not, and the trailing / or not. It should be noted that Google does not treat the trailing slash on the root domain as a separate page.
Google's John Mueller clarified what counts as duplicate content in this tweet.
I noticed there was some confusion around trailing slashes on URLs, so I hope this helps. tl;dr: slash on root/hostname=doesn't matter; slash elsewhere=does matter (they're different URLs) pic.twitter.com/qjKebMa8V8
— John ☆.o(≧▽≦)o.☆ (@JohnMu) December 19, 2017
How to fix the problem and kill your site.
Okay... "kill" is a hyperbole. But more people should care about this stuff!
You can find lots of helpful articles and forum posts on how to force https:// or how to force www. and even how to force the trailing /. But if we follow most of them we will have a new problem!
Here is a common way of fixing the problem with the .htaccess file.
## Turn on rewrite engine
RewriteEngine on
## Force WWW
RewriteCond %{HTTP_HOST} ^example\.com [NC]
RewriteRule ^(.*)$ http://www.example.com/$1 [L,R=301,NC]
## Force HTTPS
RewriteCond %{HTTPS} !on
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301]
## Remove trailing slash
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.*)/$ http://www.example.com/$1 [L,R=301]Perfect solution... right? Wrong!
Just to show you the destruction this causes let's try it on my own poor site.
Example: Redirect Nightmare on DanielMorell.com
I will start by creating a .htaccess file in the site's root directory with the following code.
## Turn on rewrite engine
RewriteEngine on
## Force WWW
RewriteCond %{HTTP_HOST} ^danielmorell\.com [NC]
RewriteRule ^(.*)$ http://www.danielmorell.com/$1 [L,R=301,NC]
## Force HTTPS
RewriteCond %{HTTPS} !on
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301]
## Remove trialing slash
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.*)/$ http://www.danielmorell.com/$1 [L,R=301]Now that I have assaulted my poor server with this monstrosity, I will test it. To test it I will enter the root domain of my website without https:// or www. and with the /. The test will be to see if it changes correctly.
I type in the URL looking like this.

When I hit the Enter key, the page loads and the URL looks like this.

You are probably wondering what the big deal is. I wanted to force https://wwww. and get rid of the trailing /. If that was the result, why am I not happy?
The problem is what you don't see.
If we take a closer look at the network requests, we will find something that should be disturbing. Here are the first three file responses from the server.

As you can clearly see we were redirected twice. We need to take a closer look at what happened.
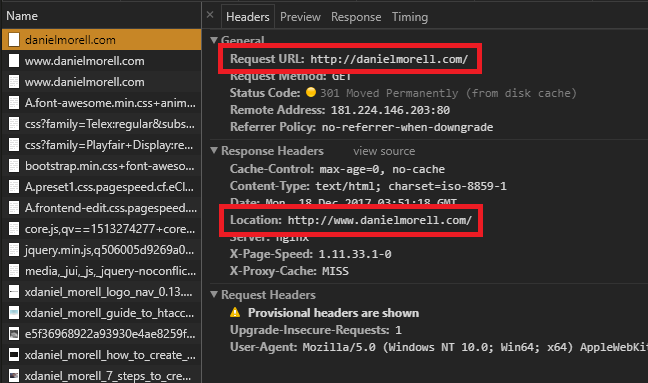
You can see that the HTTP response headers give us a clear idea of what the problem is. When we hit Enter after entering http://danielmorell.com/ we are 301 redirected to http://www.danielmorell.com/.
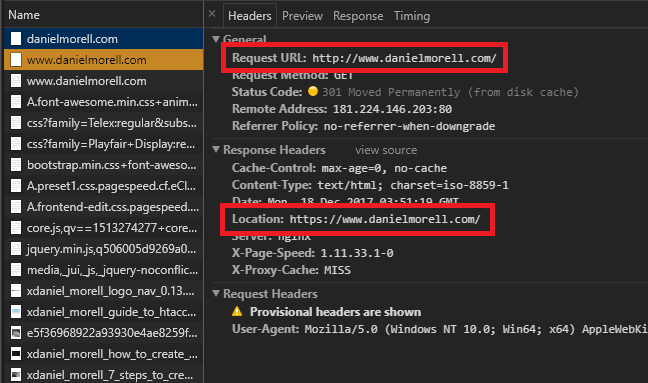
When the browser requests the "new location" http://www.danielmorell.com/ it is 301 redirected again to https://www.danielmorell.com/.
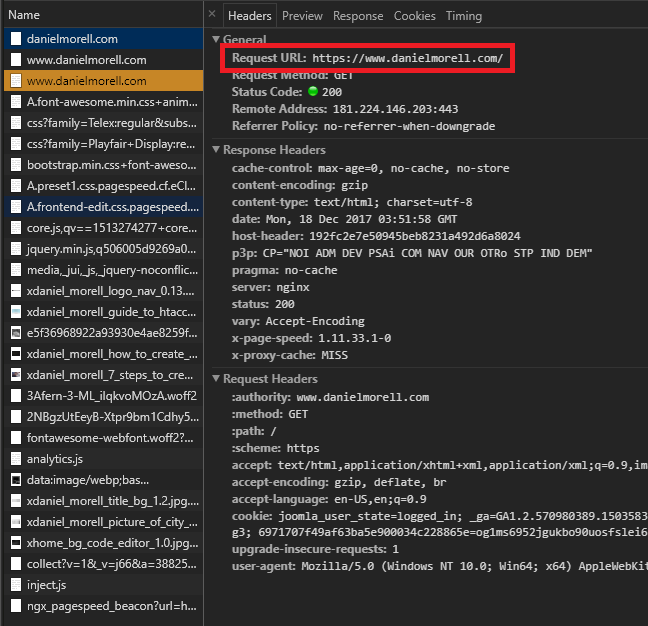
Finally, the browser tries our third location https://www.danielmorell.com/ and gets the 200 Success response.
Why was https://www.danielmorell.com/ not redirected to https://www.danielmorell.com? The reason is that it is the domain root directory. The rewrite condition for the trailing slash checks to ensure that it is not a directory. If it is a directory the last rewrite rule is ignored.
The trailing slash is removed by the browser since the response is a index.php file that has been rewritten to the domain name.
If you have been paying attention you know we have a couple problems in our example. You know that a chain of redirects is generally bad.
Redirects and PageRank
Google's Matt Cutts stated in 2013 that about 15% of PageRank is lost in a 301 redirect. This is based on Google’s concern that people would use 301’s instead of standard links so that they would pass more PageRank.
In The Anatomy of a Large-Scale Hypertextual Web Search Engine the 0.85 PageRank dampening on links was based the possibility of on a “random surfer” following the link. At its onset Google’s goal has been to rank web pages based by trying to create an algorithm that mirrors human behavior. This is why Google updated their “random surfer” model to the “reasonable surfer” model.
It is therefore no surprise that in time Google determined that 301 redirects won’t lose PageRank. A single redirect has one origin and one destination. It is not reasonable to believe that a person will browse away from a redirect once the URL that is being redirected has been requested.
It is therefore logical that in 2016 Google's Gary Illyes tweeted "30x redirects don't lose PageRank anymore."
30x redirects don't lose PageRank anymore.
— Gary "鯨理" Illyes (@methode) July 26, 2016
What does this mean for redirects and SEO? Can we have as many redirects as we want? The answer is, no. Let's not kid ourselves. PageRank is not the only ranking signal that matters. If “pumping link juice” is the only thing we care about we should get out of the SEO business.
We should look at this in terms of crawlability, indexability and quality not just PageRank. Google has stated that they won’t crawl more than five redirects.
If we were, to be honest, we would admit that we move content, and create 301s for other reasons. Instead of the normal one or two, we could be looking at five to six redirects if we are not pointing to the right protocol etc.
Example: Redirect chain in the wild
Here is an example of a careless redirect chain I found out on the wild wild web.
- Requested URL
- http://example.com/contact/
- First 301
- http://www.example.com/contact/
- Second 301
- https://www.example.com/contact/
- Third 301
- http://www.example.com/contact
- Fourth 301
- https://www.example.com/contact
- Final URL
- https://www.example.com/contact
This is enough to make a good webmaster or SEO cry.
We obviously have a problem. We need a solution.
https, www, and trailing slash with a single redirect.
The way to fix this is actually quite simple. Remember that .htaccess files like other Apache configuration files are read top to bottom. Our previous .htaccess rewrite rules checked first for www.. If that was not present it added it with a redirect. After that redirect, it added the https:// redirect. The final redirect is to remove the trailing slash.
The right way is to make the .htaccess check for the / then check for www. and https://. If any of our desired URL parameters are incorrect we use a single RewriteRule to change the URL. This method results in only one 301 redirect.
To make our redirect work properly we also must make several adjustments to the way we check for each issue.
Step 1: We will check to turn on the Rewrite Engine.
RewriteEngine OnThis is an easy one to forget.
Step 2: Check for the trailing slash on non-filepath URLs.
This is important since both servers and browsers by default place a trailing / at the end of directory URLs and not at the end of files. We want to continue following that standard.
We also want to determine if the URL ends in a trailing slash.
RewriteCond %{REQUEST_URI} /(.+)/$
RewriteCond %{REQUEST_FILENAME} !-dThe first line checks to see if we are looking at a URL that is not the root and ends in a trailing slash.
The second line ensures we are not working with a directory.
If both conditions are true we implement the following rewrite rule.
RewriteRule ^ https://www.example.com/%1 [R=301,L]This RewriteRule takes the URL from the capture group (.+) in our first RewriteCond and appends it to the domain. You can see that the site URL includes both the www and https://. This means that it will go the right location the first time.
Step 3: We need to enforce a trailing slash policy on directories.
RewriteCond %{REQUEST_URI} !(.+)/$
RewriteCond %{REQUEST_FILENAME} -dThe first line checks to make sure we are working with a path, not just the root domain. It also ensures the request ends in a trailing slash.
The second line makes sure we are working with a directory. This is important. If we left this part off we would have an endless redirect loop.
RewriteRule ^(.+)$ https://www.example.com/$1/ [R=301,L]Our RewriteRule takes the URL path requested and appends it to the domain followed by a trailing slash. The capture group (.+) captures the path only if there is one or more characters. This ensures we don't place a second / on the website root.
Step 4: We need to check to see if www. is included in the requested URL and https is the protocol or scheme used.
RewriteCond %{HTTP_HOST} !^www\.(.*)$ [OR,NC]
RewriteCond %{https} offThe first line checks to see if our www is missing.
It is important to use the no case [NC] and [OR] flags. Domains are not case sensitive. If you do not use the no case flag it may redirect on Www. since the first letter is uppercase and does not match.
The second line checks the protocol to see if it is https.
RewriteRule ^(.*)$ https://www.danielmorell.com/$1 [R=301,L]Finally, our last RewriteRule takes the requested path and appends it to the domain with the www and https added.
For this one, we use the capture group (.*) which captures zero or more characters. This ensures we redirect any request to the website root that does not have www and https.
Putting it all together. It should look like this.
#### Force HTTPS://WWW and remove trailing / from files ####
## Turn on rewrite engine
RewriteEngine on
# Remove trailing slash from non-filepath urls
RewriteCond %{REQUEST_URI} /(.+)/$
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^ https://www.example.com/%1 [R=301,L]
# Include trailing slash on directory
RewriteCond %{REQUEST_URI} !(.+)/$
RewriteCond %{REQUEST_FILENAME} -d
RewriteRule ^(.+)$ https://www.example.com/$1/ [R=301,L]
# Force HTTPS and WWW
RewriteCond %{HTTP_HOST} !^www\.(.*)$ [OR,NC]
RewriteCond %{https} off
RewriteRule ^(.*)$ https://www.example.com/$1 [R=301,L]Let's use this on my site to see what happens.
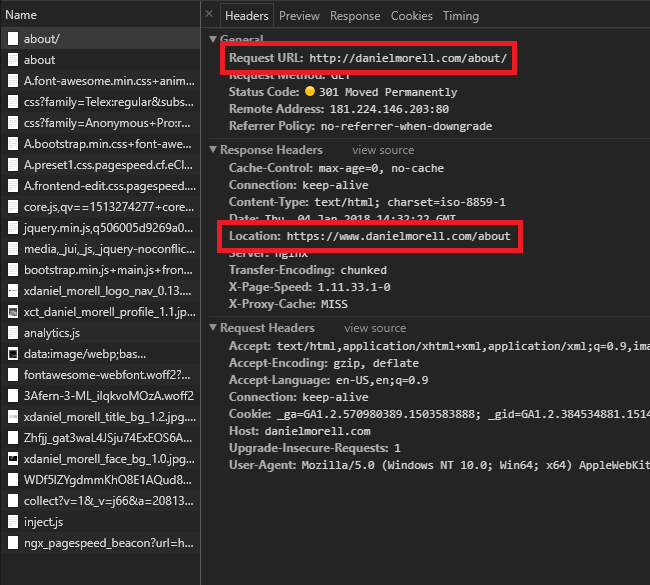
As you can see there is only one 301 redirect! This is better for your site than the redirect chain that many people use.
Never seen that before? You are not alone!
When I first wrote this guide some big-name websites had this problem. They included neilpatel.com, hubspot.com and searchenginewatch.com. You are in good company.
Most sites are at least using the two-redirect method. It is slightly better than the three-redirect method. It looks something like this.
#### Force HTTPS://WWW and remove trailing / from files ####
RewriteEngine on
## Force https and www
RewriteCond %{HTTPS} off [OR]
RewriteCond %{HTTP_HOST} !^www\.example\.com$ [NC]
RewriteRule ^(.*)$ https://www.example.com/$1 [L,R=301]
## Remove trailing slash if not directory
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} (.+)/$
RewriteRule ^(.*)/$ https://www.example.com/$1 [R=301,L]This method results in two redirects. This is not terrible, but why create two when you could use one?
There are other ways to reach a single redirect. You can store environment variables and use skip flags. However, this method seems to work best with most configurations.
Do you need a different configuration?
You can get .htaccess configuration code samples for each variation (http vs. https and www vs. no www) in the Sample Code section of this guide.
You can also use the redirect generator I created to generate SEO-friendly .htaccess redirects.
